사운들리 데이터 서버 구조 잡기
2017년 09월 18일 | humbledude

최근 사운들리는 AWS Redshift 를 사용해서 통계 데이터를 분석하기 시작했습니다. logger 서버가 수집한 로그를 S3 에 저장하고, 이 파일들을 그대로 Redshift 로 올리고, SQL 로 뽑아낸 테이블을 Tableau 로 시각화 하는 방법 입니다.
다른 팀들도 비슷한 방법으로 데이터를 분석하고 계실텐데요, 저희는 기존 시스템을 운용하다가 장애를 만났었고, 혹독한 시절을 거쳐 이를 극복하기 위해 다른 스타트업들을 방문해서 어떤 식으로 하면 좋을지를 자문을 구했었습니다. 기존 시스템 운영부터 장애 발생, 자문 및 개선까지 어떤 일이 있었는지 공유 해볼까 합니다.
저희는 AWS 에서 데이터 수집 서버를 운용하고 있었습니다. 기존 시스템은 다음과 같았습니다.
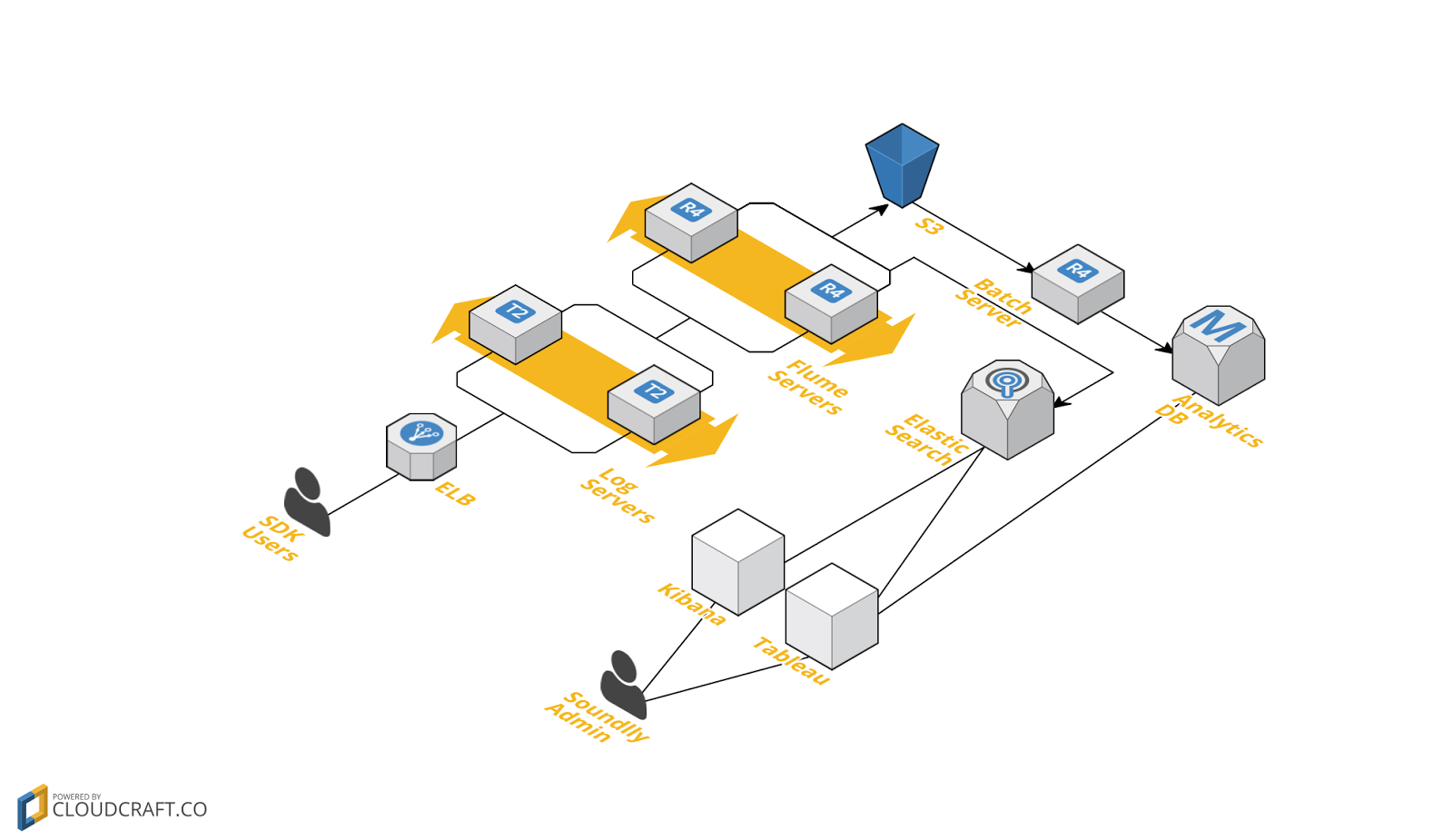
최종 시각화 결과는 Tableau 에서 보게 되었고요, Elastic Search 에 Kibana 를 붙여서 좀더 빠르고 간편한 시각화를 보기도 했었습니다. 한동안 잘 사용하고 있었는데, 큰 사업자와 제휴를 맺고 서비스를 시작하면서부터 시스템에 금이 가기 시작했습니다….ㄷㄷㄷ
맨 처음 장애는 Flume - Elastic Search 구간에서 발생 했습니다. Flume 에서 Elastic Search로 데이터를 입력하는 속도보다 Log server 에서 Flume 으로 들어오는 속도가 더 빨라지면서 발생했습니다.
Flume 의 메모리가 점점 치고 올라오면서 Flume 이 Log server 의 요청을 거부하기 시작했습니다. Log server 도 Flume 이 요청을 거부할때의 상황에 대처가 안되어있었고요.
서비스는 어찌 되었던 돌아가야 하는 상황이었으니, 특단의 조치를 내리게 되었습니다.
Flume 에서는 더이상 Elastic Search 에 데이터를 보내지 않게 되었습니다. 그랬더니 이슈는 일단 해결 되었습니다. 하지만 그로인해 Elastic Search 의 최대 장점인 실시간성을 잃었습니다. Flume 에서 데이터를 안넣으니 Batch 에서 하루에 한번 모아서 넣기로 했거든요.
이제는 평온하게 잘 운영이 된다고 생각했으나, 조금씩 더 큰 재앙이 다가오고 있었습니다. 이번에는 데이터가 너무 많아서 Elastic Search 가 못쓸정도로 버벅이기 시작했어요. 데이터를 보긴 봐야 되는데 메인 검색 엔진이 죽었으니 이를 어찌해야하나..
결국 Elastic Search 가 처리하는 데이터의 양을 제한해야 했습니다. 가장 중요하게 생각했던 dau 데이터를 제대로 못보게 되었죠. 하지만 Batch 에서 분석해서 MySQL 로 저장하게 해서 일단 dau 데이터는 MySQL 에서 보기로 했습니다.
그러나… 서비스에 연결되어있는 단말 갯수가 많아지면서 결국 Log Server 가 폭발하는 사고가 발생 했습니다. Log Server 는 트래픽 과부하로 사망했으나, 앞단의 ELB 는 살아있는 상황에서, 단말은 로그를 재전송하게 됩니다. ELB 는 단말에게 503 에러를 리턴했지만 단말은 멈추지 않았죠..ㅠㅠ 단말을 멈출수 없으니… 서비스는 일시 중지상태로 넘어가게 됩니다.
그래서 어떻게 해야 앞으로 잘할 수 있을까? 에 대한 고민으로 일단 다른 선배(?) 스타트업의 조언을 듣기로 했습니다. 분명 우리만큼의 빅장애를 겪고 삽질도 많이 했을것이다. 그것만 피해보자 라는 생각으로.. 한번 간단하게 내용을 공유 해보겠습니다.
처음 방문한 망고 플레이트에서는 전반적인 우리 서버의 문제점을 공유 드리고, 망고 플레이트의 로그 수집 및 통계 서버 구성에 대한 노하우를 여쭤 보았습니다.
개인적으로 인상깊었던 부분은, Log Server 부분이 1대당 TPS 5,000 ~ 7,000 을 버텨야 한다는거 였습니다. (그렇게만 되었다면 우리는 서비스 중지 안해도 되었을텐데..ㅜㅜ) 실제로 우리 Log Server 에는 성능을 제한하는 병목이 있었고, 그걸 개선하니 TPS 가 9,000까지도 나오게 되었습니다. 또한 서버에 장애가 발생 했을 때에도, 파일이나 MQ 같은 솔루션을 사용해서 며칠 이내에 복구 하기만 하면 되는 구조로 운영 중이었습니다. 저희가 장애에 대해 너무 대비가 안되어있다는 생각이 들었습니다.
데이터 팀에서는 Redshift 를 매우 적극 추천 받았습니다. 빠르고 싸고.. 그때부터의 좋은 인상이었는지 결국 지금 저희도 Redshift 를 쓰고 있습니다.
NBT 는 로그 수집 시스템으로 Kafka 를 사용하신다고 했습니다. 저희도 당시 Kafka 와 Kinesis 를 검토 중이었는데, Kafka 쪽에 솔깃 하더군요. 아무래도 Kinesis 는 managed service 인데 비해 Kafka 는 open source 기술이어서, 기술의 내재화 측면에서 좋은 방향으로 생각했습니다.
그리고 Elastic Search 운영에 대한 노하우를 많이 배우면서, 제품의 특성을 잘 파악해서 적재 적소에 사용해야 되는걸 우리가 잘 못했구나 하는 생각이 들었습니다. 저희는 실시간이 아니고 대규모 분석에 Elastic Search 를 쓴 격이었거든요.
NBT 는 대규모 분석에는 Spark 를 사용한다고 했습니다. 저희도 이때부터 귀가 팔랑팔랑.. Spark 를 써야하나 Redshift 를 써야하나.. 거기에 BigQuery + DataStudio 테스트 결과도 살짝 들었는데요, 이거참 Google Cloud 로 이사가야하나.. 팔랑팔랑.. 가격도 싸다는데 허허…
저희는 SDK 가 대부분의 로그를 발생시키는데 비해, 이스트몹의 센드애니웨어 서비스는 주로 각 서버에서 로그를 발생시킨다고 하셨습니다. 따라서 각 서버에서 발생하는 로그를 LogStash + Filebeat 를 사용해서 모은다고 하셨네요. 모은 데이터를 Elastic Search / HBase / Spark 를 사용해서 분석합니다.
Elastic 의 제품군을 잘 사용하시는 느낌을 받았습니다. 한 회사의 제품군이니, 정합에 있어서 신뢰도가 있을것으로 생각이 되었습니다.
또 특이한 점은 AWS 를 사용하시다가 일부 서비스는 로컬 머신에서 운용중이라고 하셨어요. 저희도 요새 서버 비용때문에 고민이 많은데, 비용 개선을 위해서는 한가지 방법만 고수할 필요는 없다는 생각이 들었습니다.
유저 해빗은 데이터 수집시에 유저의 데이터 전송량을 줄이기 위해 데이터를 모아서 압축한 뒤 전송한다고 했습니다.
서버로 전송된 데이터는 Elastic Search 쪽으로 입력하게 되고, Elastic Search 는 실시간으로 봐야 하는 데이터 규모만 운영하고 나머지는 S3 로 옮긴다고 하네요. 대규모 데이터 프로세싱에는 Spark 를 사용하고 있고요. Spark 는 S3 에 있는 데이터에 직접 처리를 실시하여 빠르고 간편하다고 했습니다.
Elastic Search 는 거의 모든 팀에서 다 잘 사용 하시더군요. 저희만 이걸 대규모 데이터 처리용으로 썼다는것만 빼고요..
Vingle 은 저희 대표님이 AWS DB Day 에서 Vingle 팀의 발표를 듣고 반해서(?) 찾아 뵈었습니다. API Gateway + Lambda + Kinesis + Firehose + S3 의 조합으로 서비스를 운영하고 계셨습니다. Serverless 구조에 대해 매우 만족하며 사용하고 계셨습니다.
이후 데이터 조회는 EMR 을 썼지만 최근에 Athena 를 쓰면서 더 싸고 빠르게 쓰고 계신다고 하셨습니다.
또한 서버 모니터링 툴에 대해서 이것저것 소개를 받았는데요, 글로벌 서비스 답게 각 나라에서의 서버 성능을 확인 해 볼수 있는 Pingdom, 장애 발생시 신속히 상황을 전달 받기 위한 PagerDuty 가 인상 깊었습니다.
레코벨도 저희 대표님이 AWS DB Day 에서의 세션에 감동하여 뵙게된 케이스 입니다. 당시 저희는 Kafka 를 써야 하나 Kinesis 를 도입 해야 하나 하는 생각을 가졌었는데요, 레코벨을 통해 Kinesis 로 확신을 갖게 되었습니다.
레코벨은 Kinesis를 중심으로 데이터를 운송하고요, S3 구조를 거의 DB 급으로 구조화 해서 사용하신다고 하셨습니다. 데이터를 쌓는 규칙을 매우 디테일하게 정의 해서 API 서버가 DB 접근하듯이 매우 빠르게 S3 에 접근할 수 있도록 했다고 하셨네요. Kinesis 는 저희처럼 개발자가 얼마 없는 스타트업에서 싸고 관리하기 쉬운 제품이라고 생각이 들었습니다.
데이터 분석은 Redshift 를 사용한다고 했습니다. 상용 Redshift 는 필요한 쿼리만 작업한뒤, 싼 가격의 PostgreSQL 에 저장하고 instance 를 내리는 방식으로 운영된다고 합니다.
다양한 팀의 자문을 받았지요? 그럼 이 내용으로 사운들리 서버가 어떻게 발전 하려 하는지 공유하고 마치도록 하겠습니다.
일단 사운들리는 작은 스타트업으로, 개발 인력이 부족합니다. 따라서 가능한 Managed Service 를 사용해서 관리 포인트를 적게 가져가는게 좋을 거라고 생각했습니다. Kinesis 처럼요. 물론 Open Source 제품을 사용해서 우리 상황에 더 맞게 사용하면 비용도 더 줄일수 있는 가능성이 있고, 사운들리 개발팀의 기술력도 올라갈꺼라는 것은 알고 있습니다. 하지만 현 상황에서 우리가 빠르게 움직이기 위해서는 관리 포인트를 줄이는 쪽을 선택 했습니다. 나중에 규모가 더 커지면 자연스럽게 Open Source 제품을 운영하게 될 것 같습니다.
그리고 사운들리는 현재 TV 광고에 음파를 실어서 그 광고를 본 사람에게 꼭 맞는 혜택을 제공하는 사업을 진행 중입니다. 그러다 보니, TV 광고라는 불확실한 요소에 트래픽이 좌우 되는데요. 그래서 처음에는 serverless 구조를 고려하게 되었습니다. 일반적인 EC2 에 서비스를 운영하는 경우, 일정한 트래픽에 대해서는 비용 / 성능 측면에서 안정적으로 운영할 수 있지만, TV 광고처럼 초단위로 춤을 추는 트래픽에는 serverless 가 맞다는 생각이 들었습니다. 하지만 호출 건당으로 과금되는 AWS 의 가격 정책은 잘 계산해서 이용해야 겠지요? 계산해보니 매우 엄청난 비용이 예상되더군요. 그래서 아직도 고민 중입니다. 돈없는 스타트업의 서러움이랄까.. 지금 저희는 EC2 와 serverless 를 적절히 섞어서 쓸수 있는 방법을 알아보는 중입니다.
데이터 분석 시스템은 맨 처음 말씀드린대로 Redshift 를 중심으로 개편 되었습니다. 기존의 Elastic Search 는 실시간 데이터 분석에 좀더 특화 하기 위해, 운영하는 데이터의 기간을 단축시켜서 빠르게 검색 하고 디버깅 하는 용도로 전환하여 사용중이고요, Redshift 는 기존의 Batch 에서 돌리던 다양한 분석 까지 커버하는 범위로 넓혀 가고 있습니다. 개발자가 일일이 개발해줘야 하던 기존 시스템에서 운영팀이 스스로 분석이 가능한 시스템으로 진화 중이에요. 그렇게 되면 개발자가 분석 개발 외에 다른 업무에 집중할 수 있게 되겠죠.
현재 진행형의 데이터 수집 서버 시스템… 과연 어떻게 될까??!
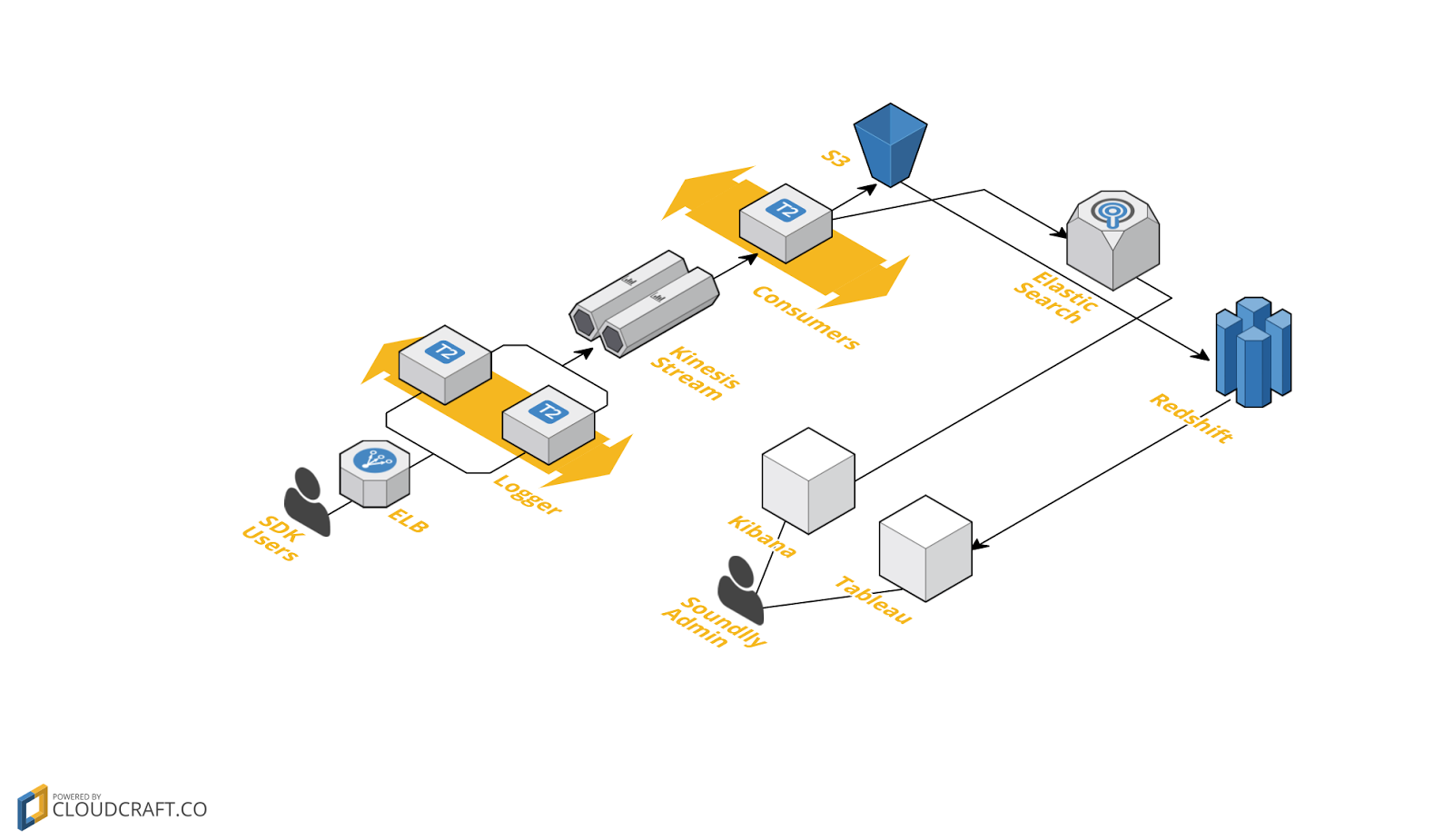
저도 서버 개발을 맡은지 얼마 되지 않은 상황에서 처음 빅장애를 겪어보니 매우 힘들었습니다. 장애 사후처리가 쉽지않더군요. 초사이어인이 죽을 고비를 넘기며 성장하는 과정과 같은 상황을 겪게 되었습니다. 그만큼 많은것을 배울 수 있는 시간이었던 것 같습니다.
다른 팀과의 교류 속에서 개발자에게는 역시 다양한 의견을 공유할 수 있는 채널이 필요하다는 생각이 들었고, 좋은 개발자와 함께 일할 수 있는게 얼마나 좋은 기회인지도 알 수 있었습니다. 그런 의미에서 사운들리에서는 좋은 개발자들과 함께 일하기 위해 채용을 지속적으로 진행 중입니다. 함께 다양한 의견을 나누며 즐겁게 개발 하시고 싶으신 분들의 많은 지원을 기다리고 있습니다.
감사합니다.
사운들리와 함께 광고 시장의 변화를 느껴보고 싶은 분들은 언제든지 문을 두드려 주세요!
